



Evaluating the Real-World Impact & Effectiveness of AI in Healthcare: Part 2
Discover the 4 essential pillars to evaluate Health AI in real-world settings—ensuring it's not just accurate, but equitable, context-aware, and truly impactful for patients and healthcare systems.

Part 1 of this article outlined that prospective studies on AI applications in real-world healthcare contexts can be used to establish evidence on its impact and effectiveness in healthcare. To establish such evidence, we are not only interested in the mere technical performance of an AI system in a prospective validation study.
Instead, it is important to evaluate whether an AI system aligns with the specific needs of the local healthcare setting, upholds core values such as equity, and demonstrates a beneficial clinical impact. This ensures trust not only in its safety and effectiveness, but also in its real-world value to patient care and health outcomes.
Sounds quite complicated? It is! This article aims to convey that there is no one-size-fits-all tool or metric that quantifies impact and effectiveness. Instead, impact and effectiveness are multi-dimensional concepts harboring a multitude of research questions. Below is a representative, though not exhaustive, list of research questions focused on assessing the impact and clinical effectiveness of AI systems in healthcare, accompanied by key research dimensions necessary to address them. These questions should be carefully tailored to each individual AI system, taking into account its specific intended purpose, the context in which it is deployed, and its relevance to local healthcare needs and priorities.
Research questions regarding impact and clinical effectiveness
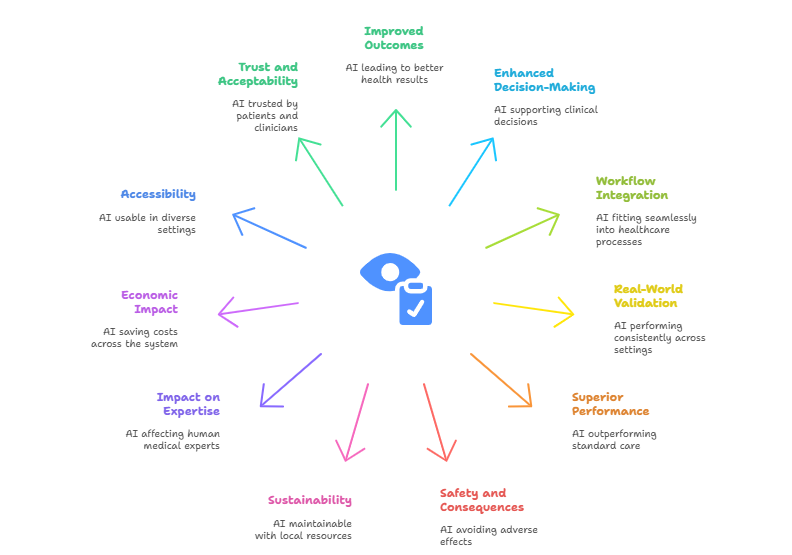
Improved patient outcomes: Does the AI system lead to better health outcomes? (e.g., earlier diagnosis, reduced disease incidence, reduced mortality, fewer complications, increased well-being)
Impact on clinical decision-making: Does the AI meaningfully support or enhance decisions made by healthcare providers?
Workflow integration and usability: Can it be used reliably in routine care without disrupting or overburdening workflows? Does the use of AI save time and how does it compare to new workload elsewhere? The use of AI may save time, e.g. for analysing a medical image, but it also adds new workload for continuously monitoring the AI system.
Real-world validation: Is the AI system performance consistent across diverse patient populations, clinical settings, and time periods?
Comparison to standard care: Does the use of AI outperform or add measurable value to current practices or guidelines?
Safety and unintended consequences: Are there adverse effects, like overdiagnosis, alert fatigue, or missed diagnoses?
Sustainability & scalability: Is the AI system maintainable with local resources? How costly is it to keep it running, monitor it or update it as conditions change?
Impact on medical expertise: How does the use of AI affect the performance of human medical experts? Are medical experts being misled by incorrect AI predictions? Is there a risk of overreliance and deskilling of human experts?
Economic impact: Does the use of AI save costs across the system—e.g., by reducing unnecessary tests, preventing hospitalizations, or optimizing staffing.
Accessibility and global relevance: Is the AI system accessible and usable in low-resource or rural settings? Was the system trained or validated using data from diverse global populations?
Acceptability & trust: Do patients and clinicians trust and follow the AI system’s output?
The Four Pillars of Health AI Evaluation
As you can see, evaluating the real-world impact and clinical effectiveness of AI in healthcare goes far beyond just looking at how much performance an algorithm can achieve. Answering these kinds of research questions is no easy task. These are complex questions, and getting clear, reliable answers requires a thoughtful and structured approach.
To help guide this process, we’ve outlined four (non-exhaustive) key pillars to tackle these research questions. Think of them as building blocks for strong, meaningful AI evaluation designed to ensure that this technology is not only effective, but also ethical and equitable when applied in real-world healthcare settings.
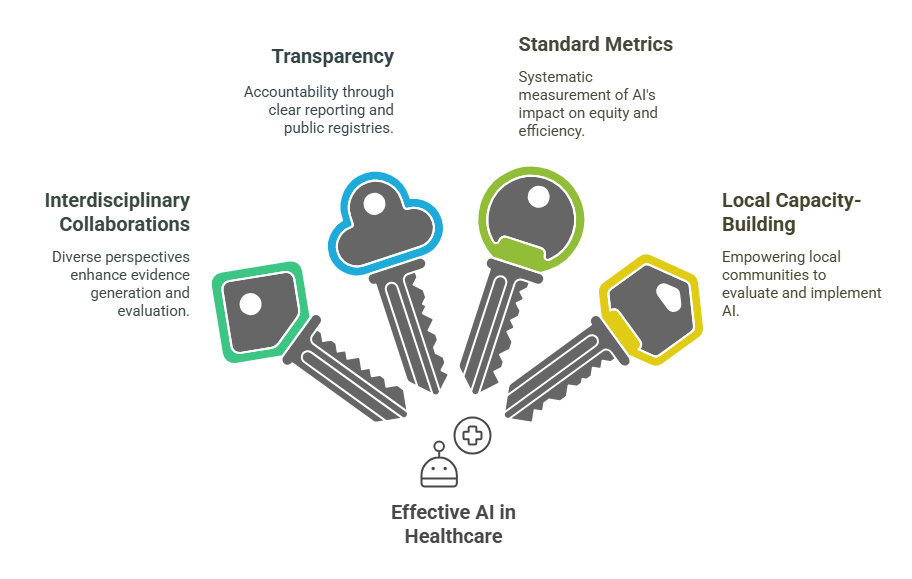
Interdisciplinary collaborations
Multiple disciplines, each hold a unique treasure chest of research frameworks to address some of these questions. For example, economics research has a long standing track record for modelling cost effectiveness of technology interventions that can also be applied to healthcare.
Global health research can provide frameworks for assessing patient outcomes, disease burden and well-being. Implementation science can provide approaches to assess the acceptability and usability of technology interventions. For all of these disciplines, the rise of Health AI offers an exciting opportunity to apply and evolve existing frameworks and tools for generating robust evidence on the impact and effectiveness of Health AI applications.
Transparency
Transparency is a crucial requirement to enable research on AI’s impact and effectiveness in healthcare. Currently there is still a lack of insight on which AI tools are implemented where in healthcare, posing a barrier to conduct this research. This insight could be facilitated through the establishment of public registries. Moreover, there is a lack of information about the design and development of AI systems, posing a barrier to investigate which decisions made during these stages contribute to improved clinical effectiveness.
Standard metrics and evaluation frameworks
Interdisciplinary consortia may need to define standardized metrics and evaluation frameworks to systematically measure the real-world outcomes associated with Health AI —such as enhancements in health equity, patient well-being, and the efficiency of healthcare systems. Such standards are crucial for ensuring comparability across studies and settings.
However, it is equally important that these frameworks maintain sufficient flexibility to account for the wide range of contexts in which AI technologies are implemented, particularly given the diversity in healthcare infrastructure, population needs, and resource availability.
For example, global health systems differ significantly in terms of infrastructure, resources, population health needs, and data availability, making it unrealistic to apply a one-size-fits-all evaluation framework. Evaluation frameworks may also need to be adapted to the type of AI.
For example, the rise of Large Language Models (LLMs) in healthcare likely require adaptations of traditional AI evaluation methods, because their outputs are typically text-based and open-ended. Their outputs pose clinical effectiveness questions regarding consistency, plausibility and harmful outputs rather than accuracy.
Local capacity-building
Ultimately, establishing local capacity at each deployment site is essential for generating robust, context-specific evidence on the impact and effectiveness of AI in healthcare, and for ensuring the responsible and sustainable integration of these technologies. Developing in-country expertise enables more timely and adaptive evaluations that can respond dynamically to emerging challenges, support iterative improvements, and enhance the overall performance of AI systems in real-world settings.
Moreover, local capacity can facilitate the translation of evidence into national health policies, promoting informed decision-making that aligns with local priorities and health system goals. This is particularly critical for AI tools developed in different countries; independent local evaluators, free from commercial influence, can assess whether such technologies meet local needs and uphold key values such as equity, data privacy, and public trust—ultimately ensuring that the benefits of AI are equitably realized by the communities they are intended to serve.
Thanks for reading! I hope this blogpost gave you a few insights and inspiration on how to strengthen the evidence on AI’s real-world impact and effectiveness. If you are finding this blogpost here, you are likely to find a like minded community at the Health AI for All Network (HAINet). Come join us!
Have questions or thoughts on the topic? We welcome your insights—feel free to share your comments or start a conversation below.

Jana Fehr is an AI researcher with a passion for the transformative potential of artificial intelligence in healthcare. With a background in biotechnology and machine learning, she enjoys bridging the gap between technology and medicine to develop responsible practices about the integration of AI into medical practice.
 | A guest post by
|