

Understanding Alignment in Vision Language Models (VLMs)
At the core of VLMs lies the fundamental challenge of representing image feature vectors as LLM textual vectors while preserving the information. This blog explores how this alignment is supervised.

LLMs and VLMs
Large Language Models (LLMs) are designed to understand and generate text. For a given input, they operate by converting the text into vectors, mathematical representations that capture the features of the text. These features can include emotions, positivity or negativity, semantic meaning, and many other subtle factors that often go beyond the current limits of human explanation.
A Vision Language Model (VLM) is an extension of LLMs, but with the added ability to understand images. This is done by representing an image as vectors in a similar way to text. To generate these image feature vectors, we often use models such as ResNets or Vision Transformers (ViT), which are highly effective image encoders.
Misalignment
However, simply passing image vectors directly into an LLM does not work well. This is because the features captured by vision encoders may have very different meanings compared to the features understood by language models.
You can think of this as a language barrier: the “language” of the vision encoder is not directly interpretable by the LLM. To bridge this gap, we need a projection layer, which aligns or translates the representations of images and text into a shared space. This alignment allows VLMs to connect vision and language effectively.
Training the Alignment Model
One of the most influential techniques for aligning image and text features is CLIP (Contrastive Language-Image Pre-training), introduced by OpenAI. The idea is simple but powerful. OpenAI collected hundreds of millions of image-text pairs from the internet.
During training, the model is shown a batch of images and their associated captions. For each correct image-text pair, the model is incentivized to increase their similarity score, while simultaneously decreasing the similarity scores of incorrect pairs.
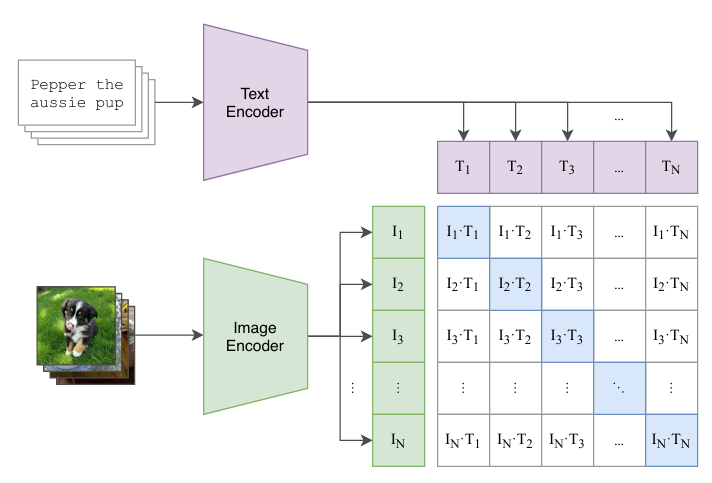
The objective can be visualized in a matrix, where the diagonal entries (correct matches) should have the highest similarity, and the off-diagonal entries (incorrect matches) should have much lower similarity.
By repeating this process millions of times over massive datasets, CLIP learns a shared embedding space where images and text are aligned. In this space, an image of “a dog running in the park” will be close to the caption “a dog running in the park” and far from irrelevant captions like “a bowl of pasta.”
Use Cases of Vision–Language Alignment
Once trained, models like CLIP become extremely versatile. Because they have seen such a wide variety of real-world data, they can be applied to many tasks without additional fine-tuning. Some notable use cases include:
1. Zero-Shot Classification
Instead of training a separate classifier for every task, you can simply describe the classes in natural language. For example, if you want to classify an image as either cat, dog, or horse, you can embed these text descriptions and compare them with the image embedding. The class with the highest similarity score is chosen as the prediction. This enables flexible classification without task-specific training data.
2. Image Search and Retrieval
With aligned embeddings, you can perform text-to-image search or vice versa. For instance, typing “a red car on a snowy road” will retrieve the most relevant images from a large database. Similarly, you could input an image and retrieve text descriptions or find similar images.
3. Content Moderation
Platforms can use VLMs to detect and filter harmful or inappropriate content. Because the model understands both images and their semantic context, it is more effective than traditional computer vision methods that only look at pixel patterns.
4. Image Captioning and Description
By combining CLIP-like encoders with generative models, VLMs can generate detailed captions for images, making them useful for accessibility (e.g., describing photos to visually impaired users).
Final Thoughts
Vision Language Models represent a major step towards multimodal AI, where systems can understand and reason across different types of information. The success of models like CLIP shows how powerful large-scale contrastive learning can be in aligning two very different modalities.
As the field grows, we can expect VLMs to become more accurate, more general, and more deeply integrated into everyday applications—from search engines and educational tools to medical imaging and accessibility technologies.
Thank you for reading!